
By John Patzakis and Ashley Aranega
Over the past two weeks, stock traders fueled by Reddit message boards have engaged in a classic short squeeze that could involve potentially illegal behavior. Financial crime investigators as well as corporate risk and eDiscovery teams are scouring Reddit to identify and preserve critical evidence. With the stakes high, such investigations must be performed consistent with best practices in order to properly preserve and analyze data within pressing time constraints. Here are three key tips to help investigators to be as complete and efficient as possible.
- Automated Web Capture with Native Format Collection is a Must
Financial investigations of this scope require the analysis of thousands if not tens of thousands of social media posts and web pages. Flat file screen grabs will not do the job because they cannot be collected at scale, readily searched, nor organized in a streamlined manner. An investigator must be able to capture a single thread expanded to include up to hundreds of comments per post or crawl an entire publicly available Reddit Account collecting up to thousands of posts by that user on an automated basis. Once captured, the data must be searched, analyzed, and tagged all in line. None of this is possible with a manual print screen effort.
- The Investigation Should Include Other Social Media Sources and Web Feeds
Here is a very notable Tweet from Elon Musk:

He is directing people to a Reddit board where speculative investors congregate and plan short squeeze activity. Musk’s ill-advised social media posts have gotten him into previous trouble with the SEC, and this Tweet could be pushing the envelope. It demonstrates why multiple web sources and social media accounts are essential to cross-reference and consolidate as evidence. Your social media investigation and analysis platform should enable you to search, sort, and analyze multiple social media accounts from different sources, all in the same interface. This again is impossible with screenshot based tools and workflows.
- Native and Granular Output is Critical
Securities fraud investigations often involve copious amounts of web-based evidence. It is extremely difficult to collect and analyze thousands of Reddit posts without the right technology. It is even more difficult to process and load those items into an attorney review platform if they are simple screenshots. Print screen as a social media evidence collection method only leads to higher costs for many reasons, namely because the resulting output is a truncated, unsearchable, flat image that fails to retain the all-important metadata. As a result, a substantial amount of secondary processing must be done to upload the social media images into a standard attorney review platform. The images must be run through OCR, the various requisite metadata fields must be manually entered, and the truncated screenshots reassembled into context, so they appear and read as they did in their original state. All this will typically cost thousands of dollars in additional processing fees.
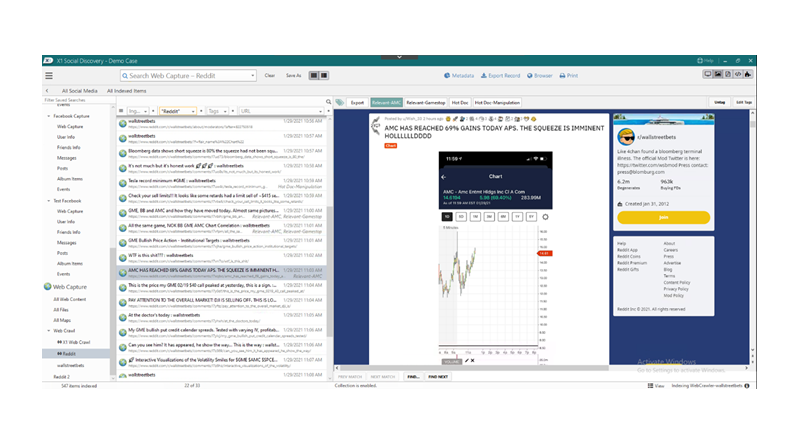
Above is a screenshot of key Reddit evidence captured by and displayed in X1 Social Discovery. X1 Social can capture a single thread or crawl an entire Reddit account, collecting up to thousands of posts by individual users on an automated basis. Once captured by X1, the data can be effectively searched, tagged, and exported out to load file or in native format as well as PDF. X1 Social Discovery is the most comprehensive and efficient tool for Reddit collections. Tweets, Reddit posts, and other social media evidence can be exported in one fell swoop into the same deliverable. Simply put, for serious web-based securities investigations, there is no other option.





